Coding built on your data — proven against your claims.
Capsa encodes your guidelines, reads the signed note, and recommends every CPT/HCPCS code the chart supports with a plain-English reason — verifying each quote is verbatim in the chart before a coder sees it, then scoring itself against what your coders actually billed. 93–96% accuracy.
Both ways coding goes wrong are expensive.
After a provider signs a note, a coder reads it and bills every service performed. Billable work is easy to miss, inconsistent between coders, and hard to audit after the fact.
Lost, fully compliant revenue — gone for good
Billable work the coder didn't capture is money you earned and won't see. At scale, a few missed codes per visit is a seven-figure annual leak.
Audit risk and clawback exposure
Codes billed without support in the chart invite denials and recoupment. The goal isn't “more billing” — it's the right amount, provably.
You don't buy AI prompts — you get the pipeline.
Capsa turns your own material into a living coding system: your guidelines, cohorts, coding patterns, and paid claims drive a loop you control.
Build
Encode your rules, codes, and worked examples into an explicit, human-readable guideline.
Validate
Compare predictions to what your coders actually billed — scope-aware precision and recall.
Adjust
Refine rules from real disagreements, applied as traceable, versioned diffs.
Monitor
Track accuracy continuously over time as documentation and payers change.
Read the note. Prove the code. Measure against what was billed.
Ingest
The signed note comes in from the EHR; augmenters fill known gaps like structured vaccine records.
Triage
A fast model decides which coding categories even apply, so effort goes only where it's needed.
Analyze
Each category runs an explicit, human-readable rule set and proposes codes with a plain-English reason.
Cite-check
Every quote is verified verbatim in the chart. Unsupported recommendations are dropped before a coder sees them.
Validate
Predictions are scored against what the coder actually billed — scope-aware precision and recall.
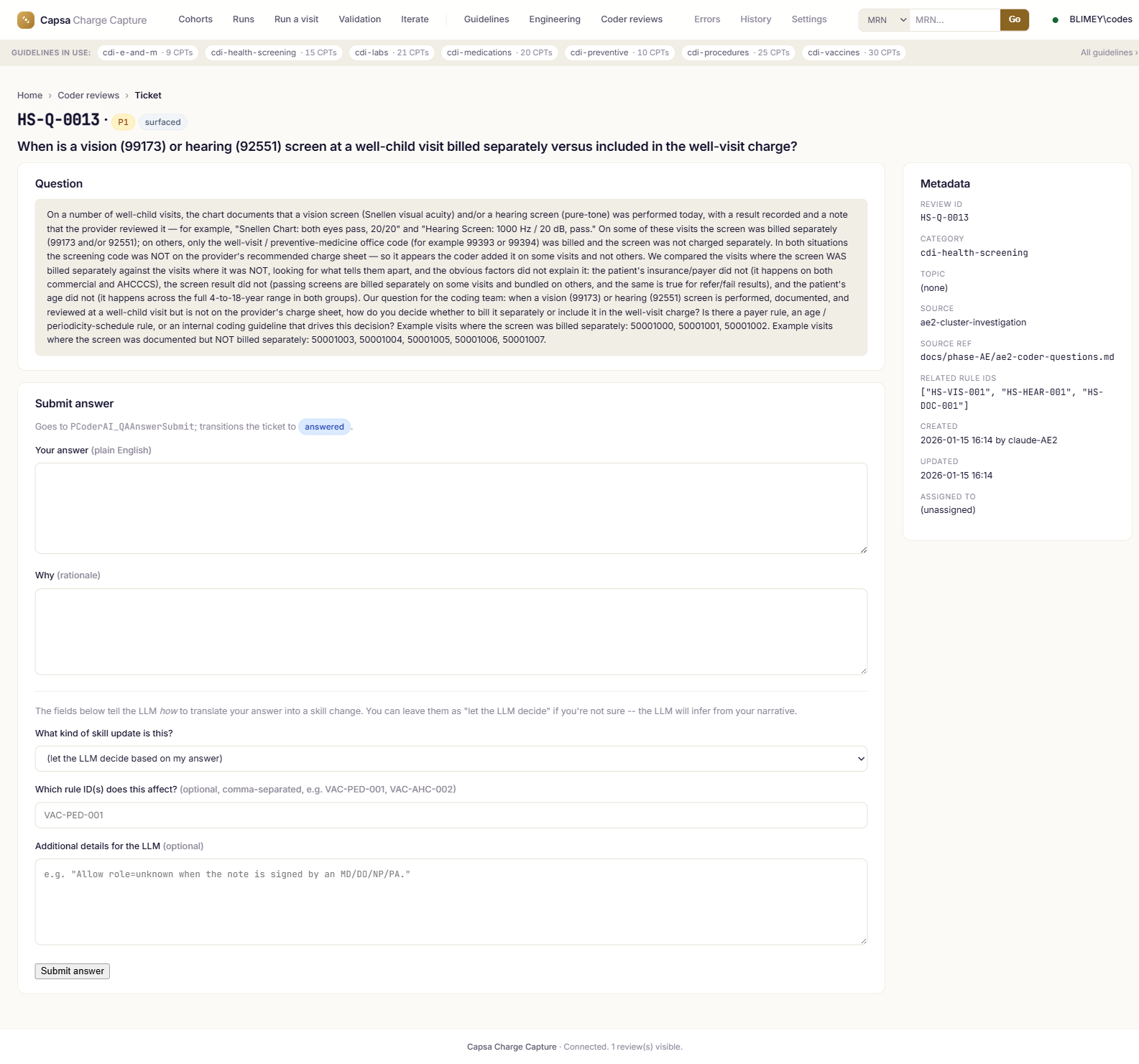
Real screens from the product.
Screenshots are from the live application. Patient identifiers and clinical text are scrubbed; codes, rules, versions, and metrics are real.
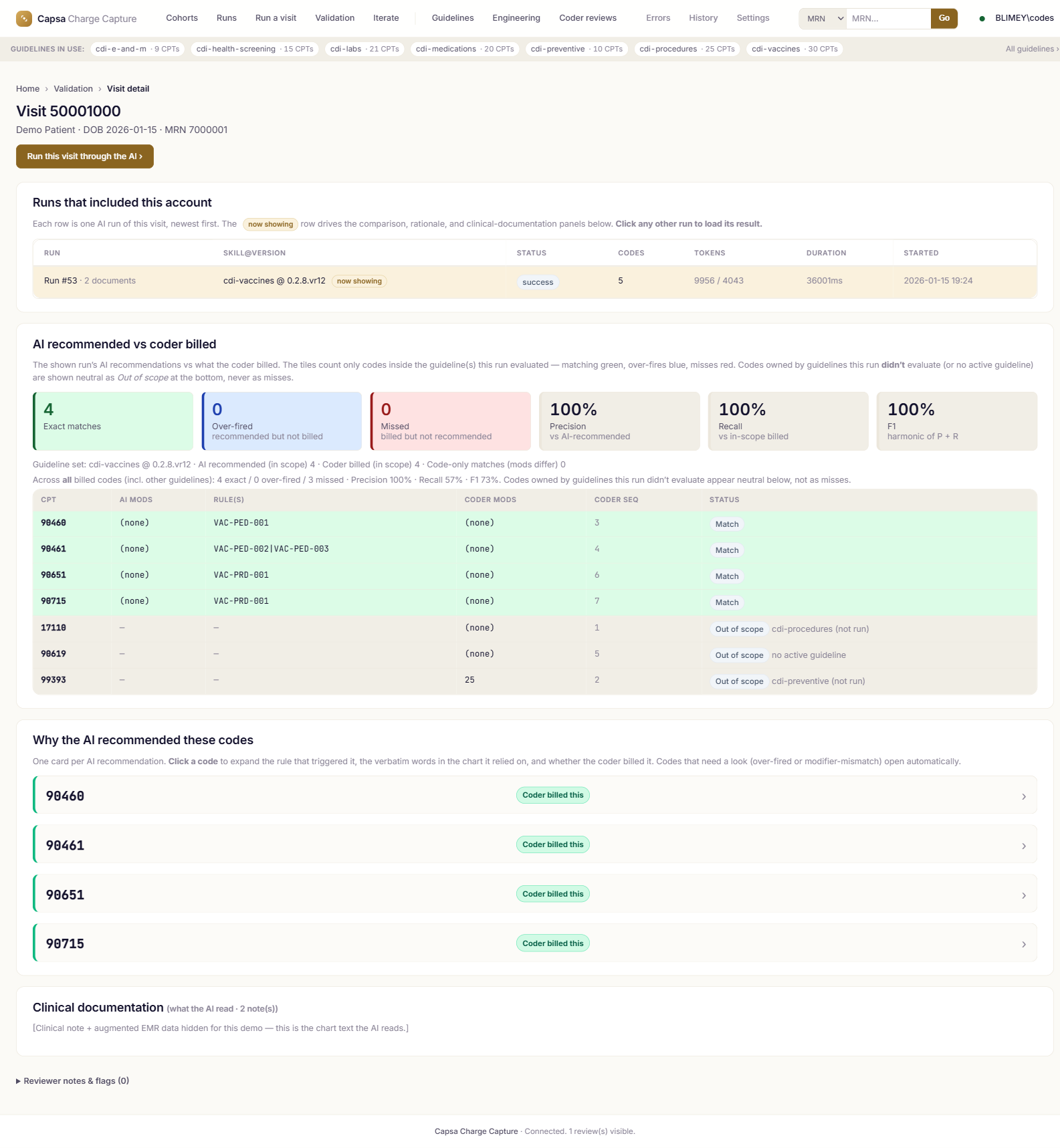
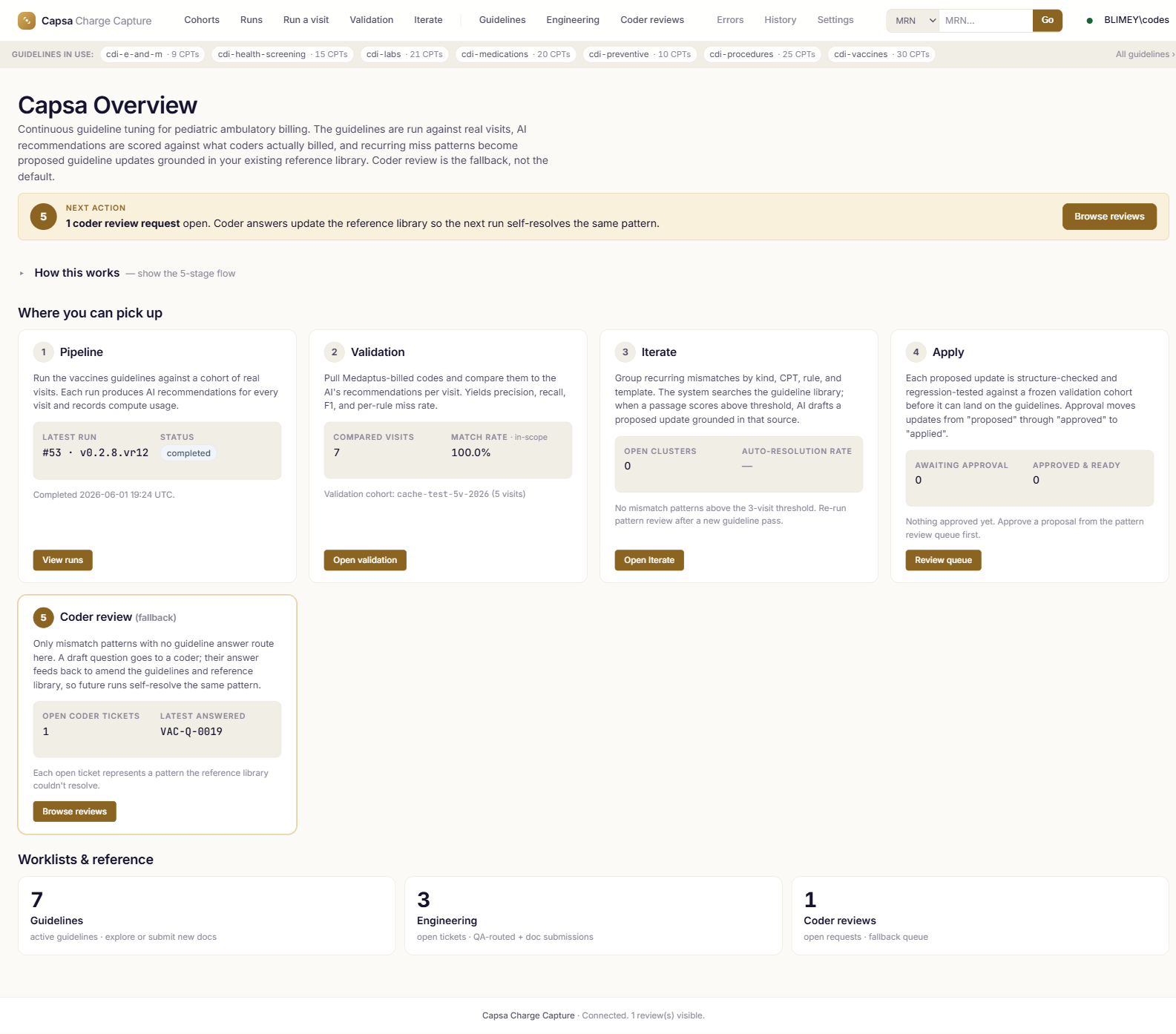
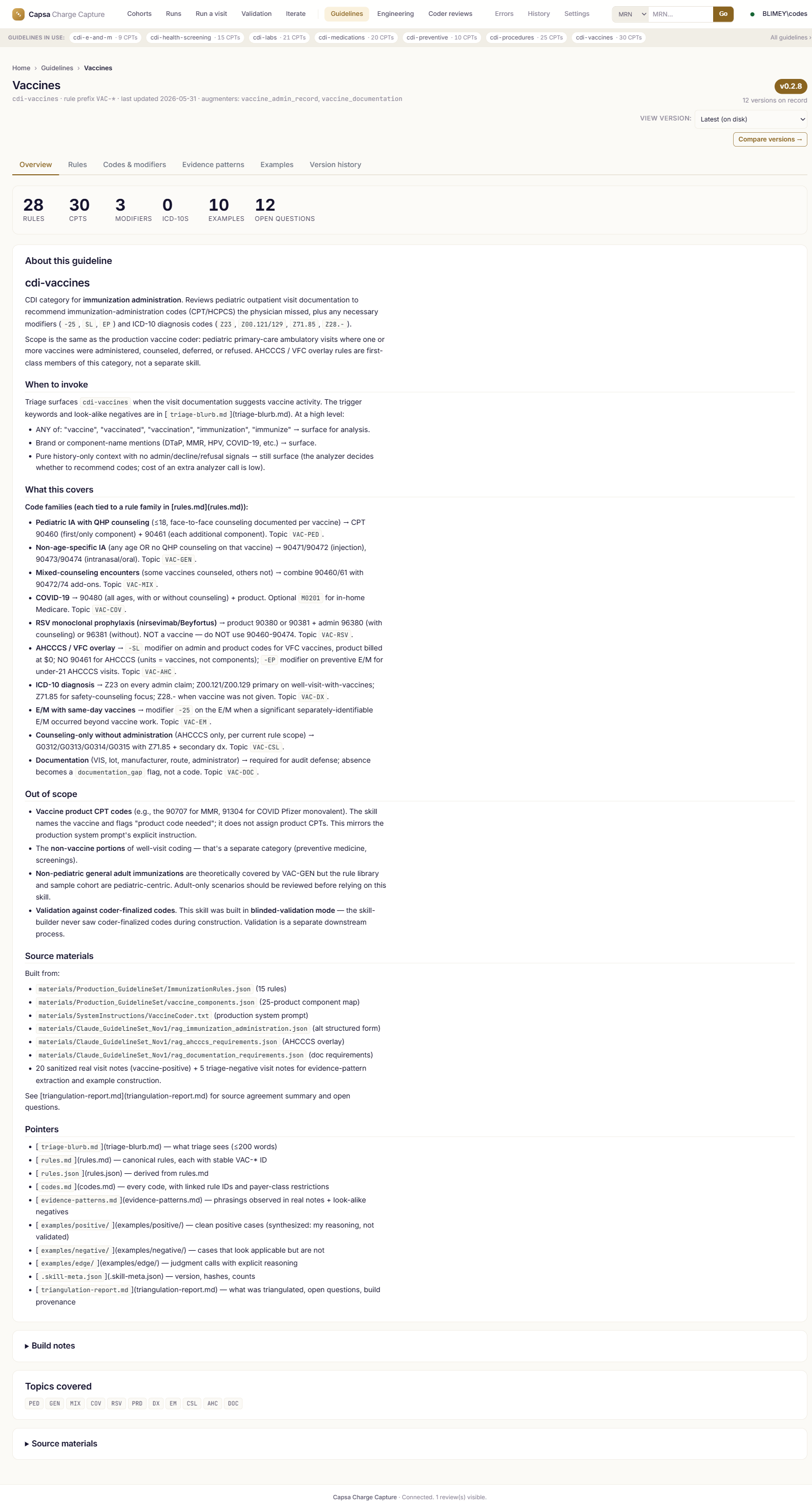
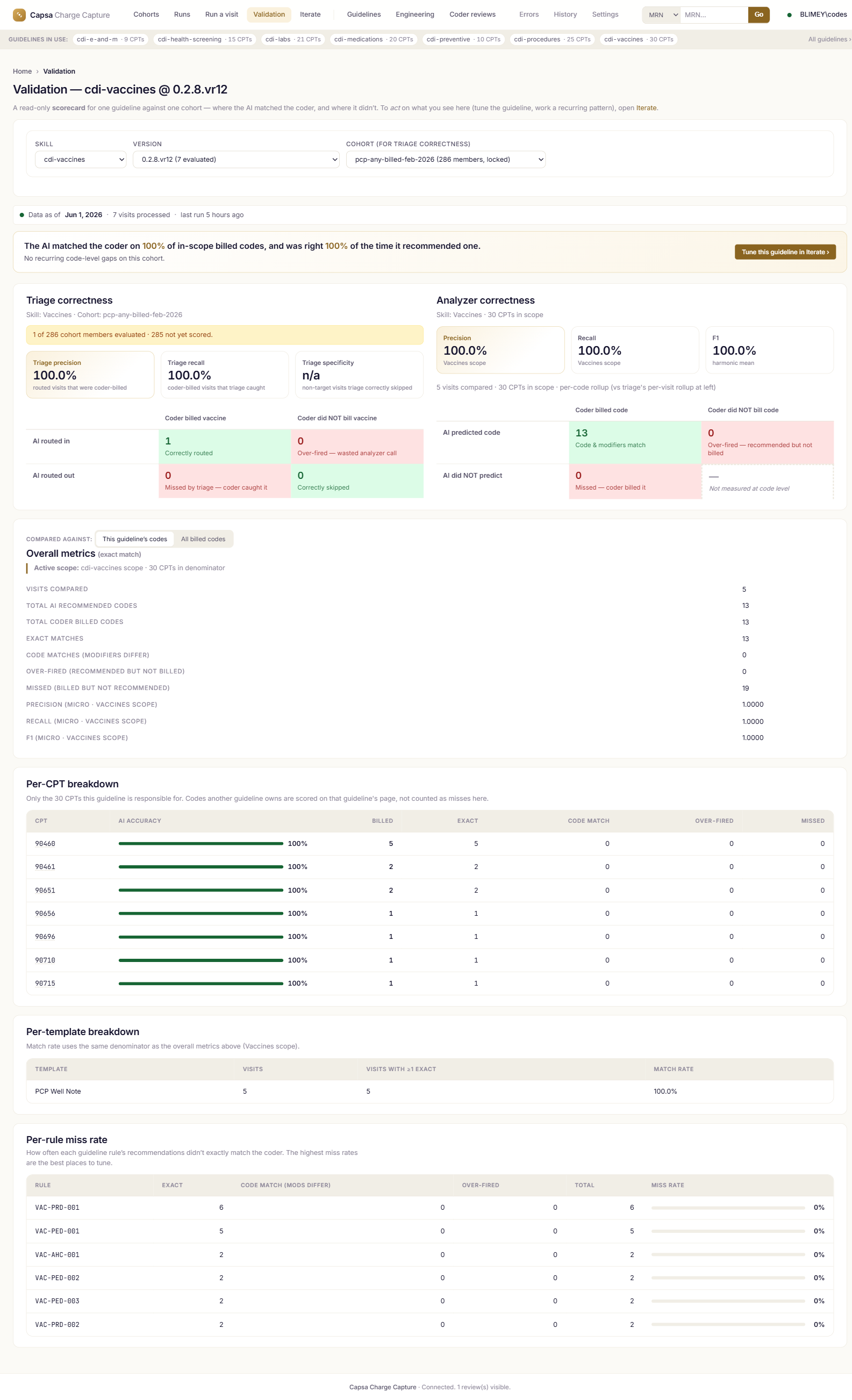
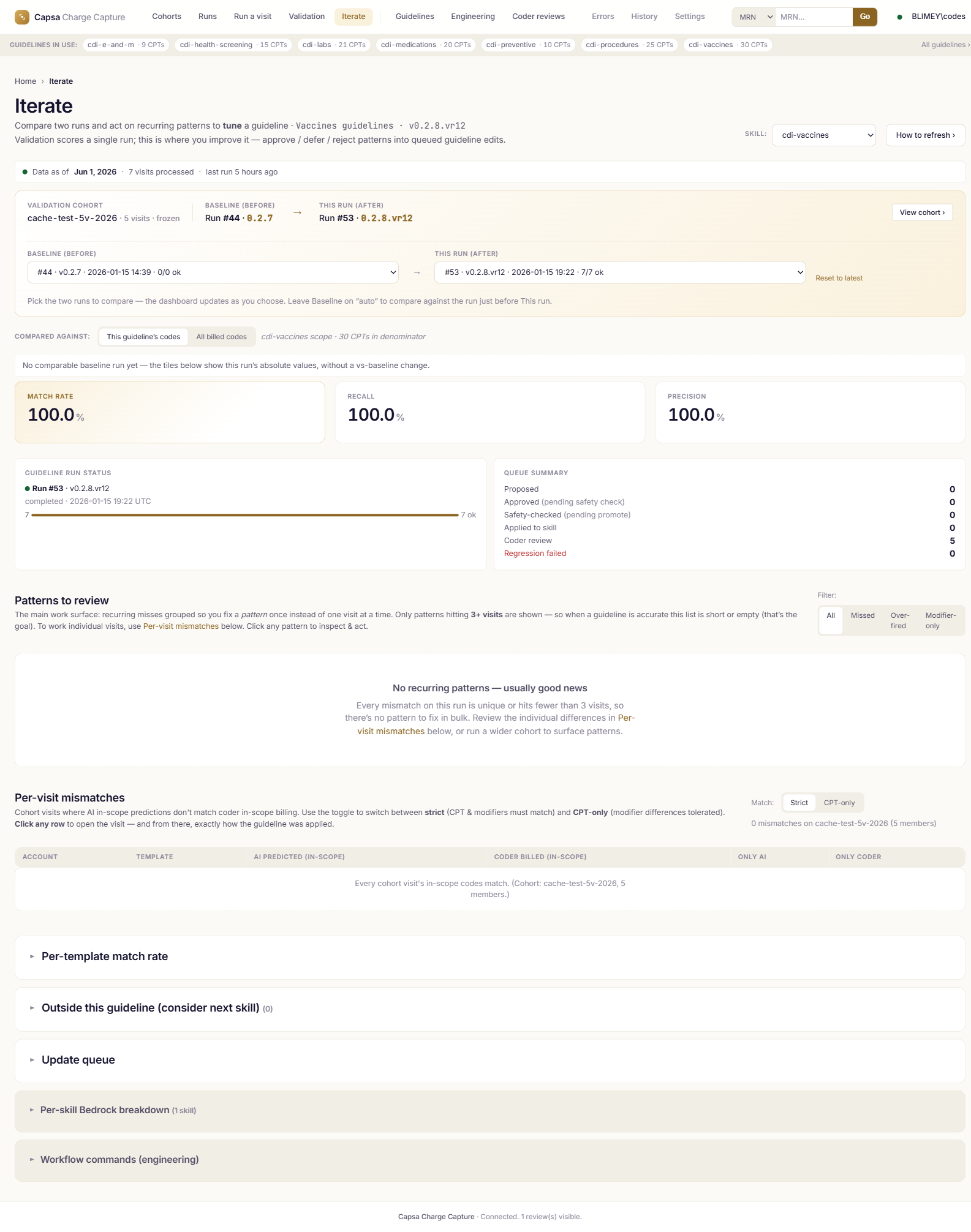
Measured on cases your team already coded.
Precision = of the codes Capsa recommends, the share coders agree with. Recall = of the in-scope codes coders billed, the share Capsa caught.
93–96% accuracy across our two measured categories
Vaccines and health screening are measured and proven against what your coders actually billed; five more categories are built on the same framework, measurement in progress.
| Coding category | Precision | Recall | Note |
|---|---|---|---|
| Vaccines | 96.9% | 95.5% | Recall SLA (≥95%) met; precision at target. |
| Health screening · A | 93.7% | 95.7% | Recall SLA met. |
| Health screening · B | 93.9% | 93.4% | Both metrics near target. |
“If your human coders can code it, the AI can too.”
Internal, validated results across two live coding skills, measured on cases your team already coded. Not an external certification.
Transparent by design — and yours to govern.
Every code traces to the chart
Code → rule → the verbatim chart text that triggered it, at the exact version that ran. Unsupported quotes are dropped before a coder ever sees them. Answer “why this code?” in one click.
Versioned and auditable
Rules, codes, evidence, and worked examples are versioned together with full history and side-by-side diffs. When a payer rule shifts, the change is on the record.
Scope-aware measurement
Precision and recall are measured against the codes each skill actually owns — so the numbers mean what they say instead of being diluted by out-of-scope codes.
Clinician-governed loop
CDI nurses — not engineers — answer clarifying questions and approve rule updates through a guided workflow, with a complete audit trail.
Built on your data
Your guidelines, cohorts, coding patterns, and paid claims drive the system — so it fits your hospital instead of a stranger's static prompt set.
No model lock-in
One engine runs every category, wired to no single EMR or guideline source. All logic lives in explicit rule sets — not weights baked into a model.
See the whole loop, end to end.
A two-minute walkthrough of build → validate → adjust → monitor on real screens. Prefer a live look on your own data? Book a pilot.
Questions coders, CDI, and compliance ask.
Is this just generic AI prompts?+
How is this different from a black-box coding model?+
Will Capsa replace our coders?+
How do you measure accuracy?+
Is it audit-defensible?+
What does a pilot involve?+
How do you handle PHI and data security?+
See Capsa on cases your team already coded.
We'll build a guideline from your rules, run it against your cohorts and paid claims, and show you scope-aware precision and recall on visits you've already billed. No rip-and-replace.
- Built on a sample of your own visits
- Accuracy measured vs. what your coders billed
- Every recommendation cited to the chart
- No EMR or vendor lock-in
Request a demo / pilot
We'll get back to you within one business day.