AI medical coding,
built on your data.
Capsa reads the note the way your best coder would and finds every billable charge the documentation supports — each one defensible, cited to the exact words in the chart. Then it does it on every visit, at once — the read no coding team could staff, at a fraction of the coder hours. Built on your data, measured against what your coders actually billed.
Published coding guidelines are only half the job.
After a provider signs a note, every service performed has to be billed — the vaccines and screenings, the labs and procedures, the medications, and the visit level itself. Easy to miss, inconsistent between coders, hard to audit later.
Lost, fully compliant revenue — gone for good
Billable work the coder didn't capture is money you earned and won't see. At scale, a few missed codes per visit is a seven-figure annual leak.
Audit risk and clawback exposure
Codes billed without support in the chart invite denials and recoupment. The goal isn't “more billing” — it's the right amount, provably.
A stranger's AI prompts can't code for your hospital.
Most “AI coding” is a fixed set of prompts written by an engineer somewhere else and dropped into your hospital — never adapted to it. Capsa is the opposite: it's built on your data.
Generic, off-the-shelf AI
A static prompt set, identical for every customer — blind to everything that makes coding work at your site:
- Your providers' documentation phrasing
- Your payers' contract and visit rules
- Your team's established coding patterns
- Your own paid-claims history
Capsa, built on your data
Your own data becomes the system — so it learns exactly the context a stranger's prompts can't see:
- Your providers' documentation phrasing
- Your payers' contract and visit rules
- Your team's established coding patterns
- Your own paid-claims history
Good coders quietly tune their work to each hospital.
Hand the same signed note to coders at two different hospitals and you can get two different — equally correct — claims. What changes is local: the wording providers use, the payers, and how the team has always coded it.
Same note.
Same services performed.
Coded differently depending on where it happened — because three things change per site.
Documentation habits
Which phrases this site's providers actually use to record the work.
Local payer rules
Contract and visit conditions specific to this hospital's payers.
Coding patterns
How this team has historically coded similar encounters.
You don't buy off-the-shelf AI — you get coding built on your data.
Capsa turns your own material into a coding system that fits your hospital — your guidelines, a sample of your past visits, how your team codes, and what payers actually paid drive a cycle you control.
Build
Encode your rules, codes, and worked examples into an explicit, human-readable guideline.
Validate
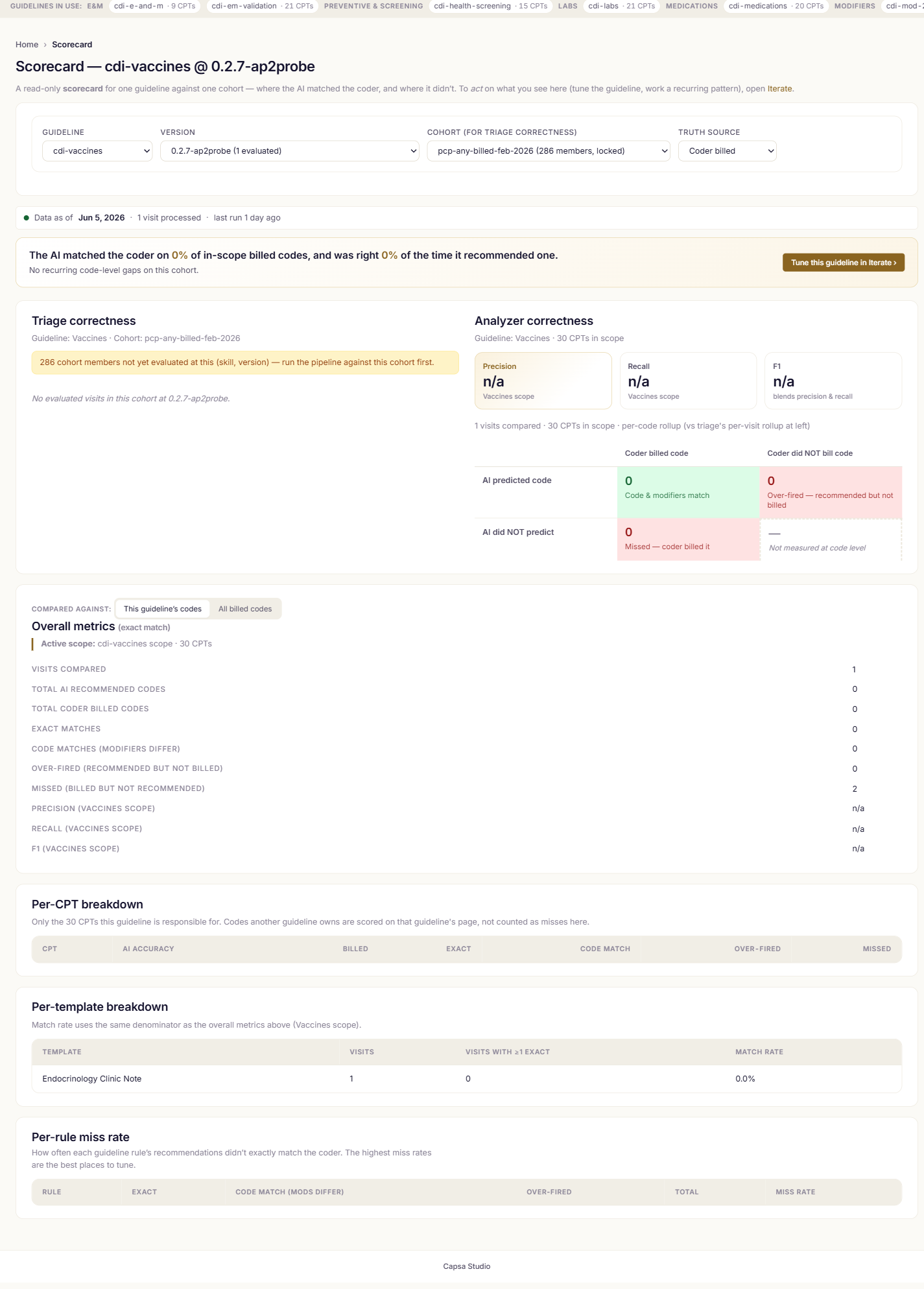
Compare Capsa's codes to what your coders actually billed — precision and recall on the codes that matter.
Adjust
Fix the rules from real disagreements — every change tracked and versioned.
Monitor
Keep watching accuracy over time as documentation and payers change.
coding accuracy, measured against what your coders actually billed.
“If your coders can code it, Capsa can too — on every visit.”
Internal, validated results across two live coding skills (vaccines and health screening), measured on cases your team already coded. Not an external certification.
See where charges slip away.
Every charge passes through several hands: the doctor writes the note, a coder turns it into a claim, the payer decides what to pay. Money can fall out at each step. Capsa checks the whole path and shows you exactly where — and how much you could recover.

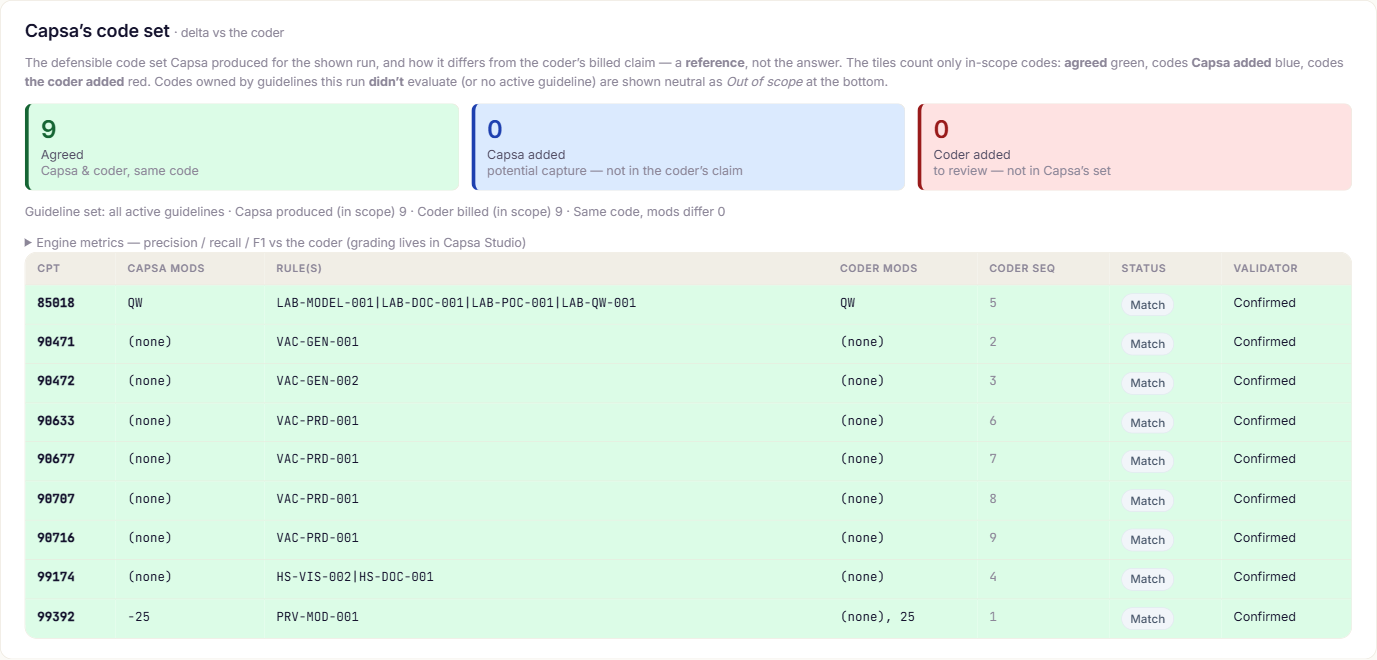
Transparently benchmarked against your coders.
During validation, Capsa’s codes sit next to what your coders billed — every code carried by the exact line of the note that supports it — so you can see, down to the visit and the code, that it codes as well as or better than your team. In production Capsa just codes; the benchmark is how you earn that confidence first.
One coding engine — an app for each job.
Capsa reads the note and builds one defensible code set. Three applications put that to work for three teams: coders finalize the claim, revenue-cycle leaders oversee the lifecycle, and your clinical team builds and proves the coding itself.
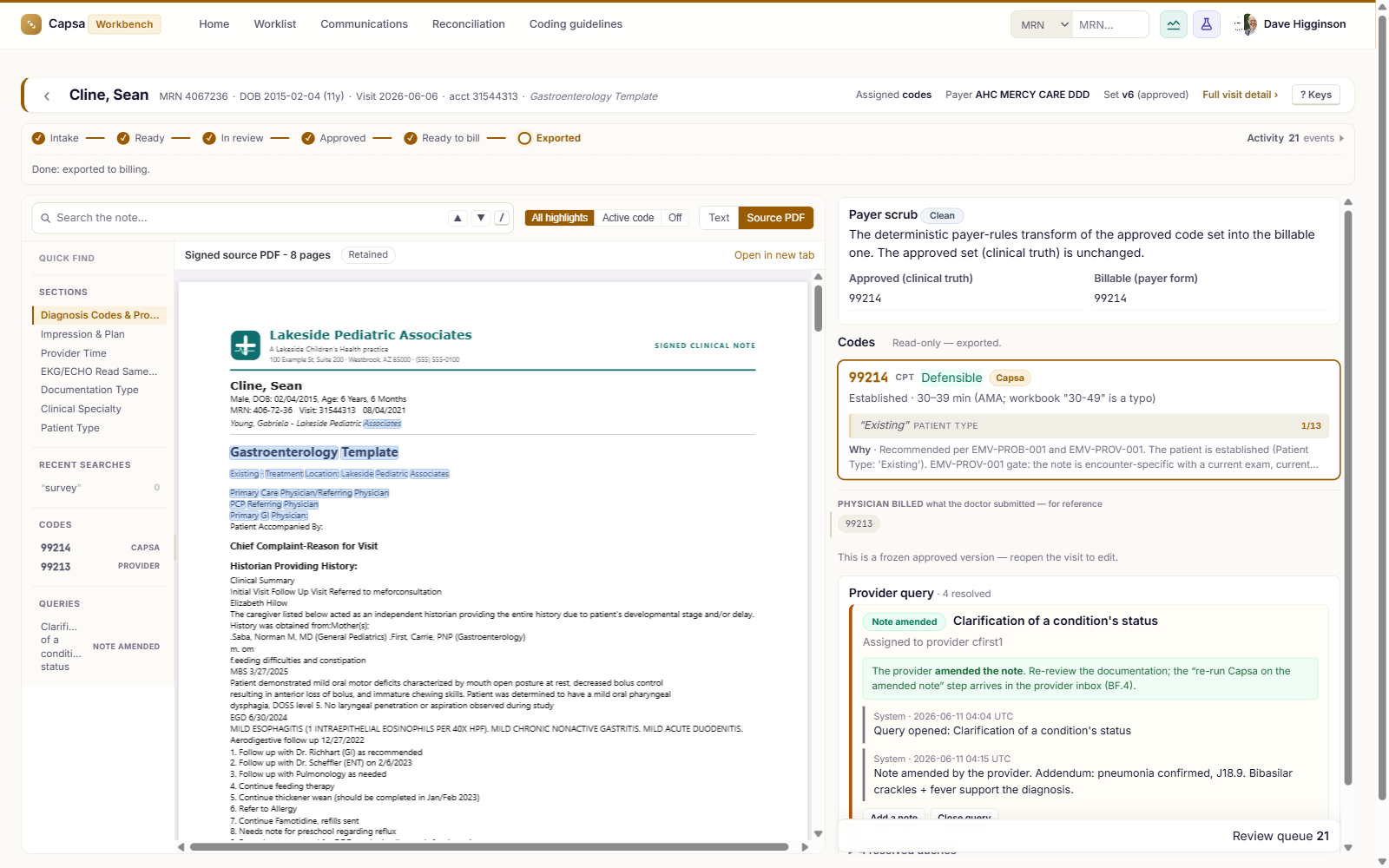
Finalize the claim
Every code cited to the chart, the provider a click away, the claim finalized without leaving the note.
Explore Workbench →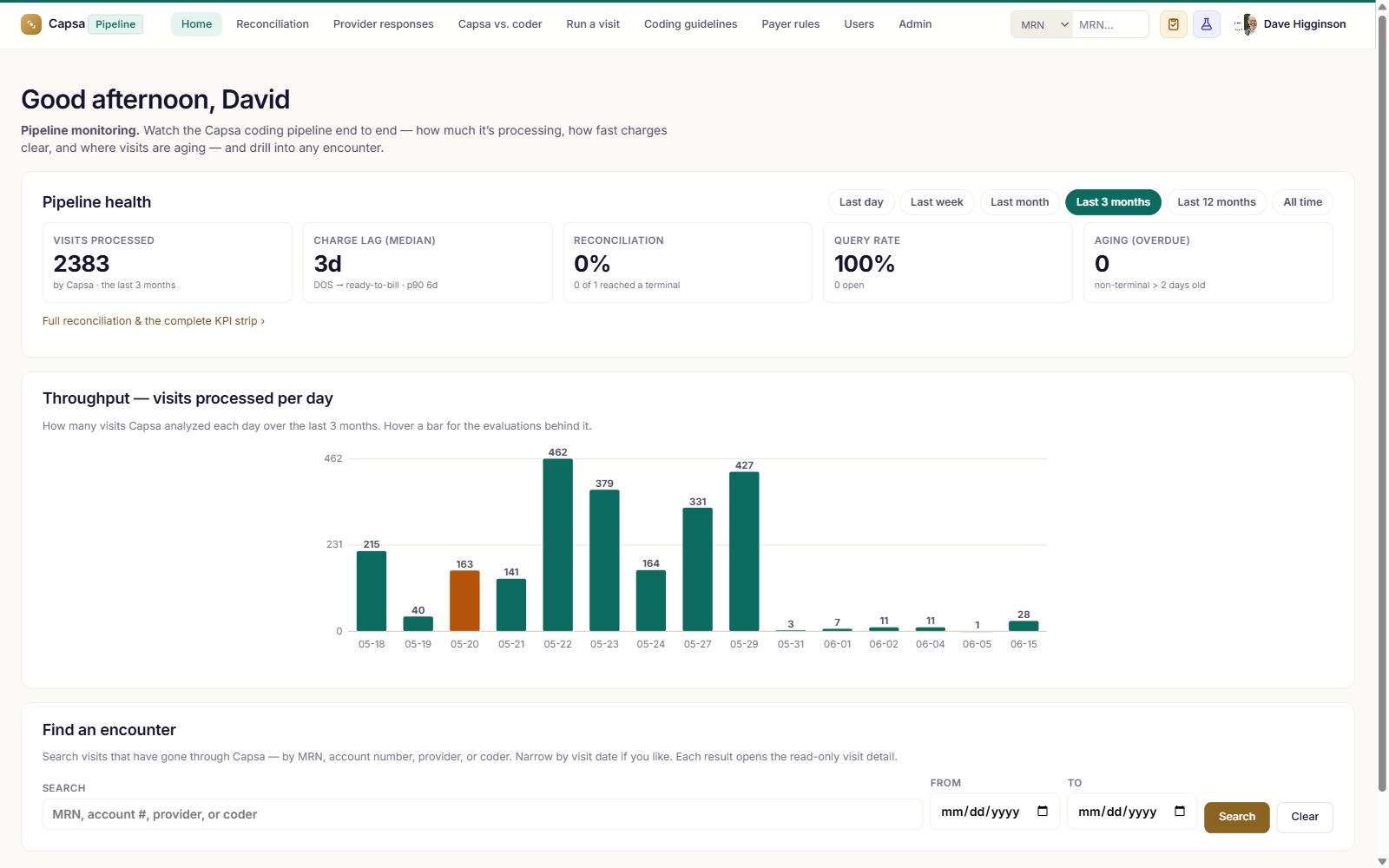
Oversee the lifecycle
Throughput, billing lags and bottlenecks, and the charges Capsa captures — the whole pipeline, live.
Explore Pipeline →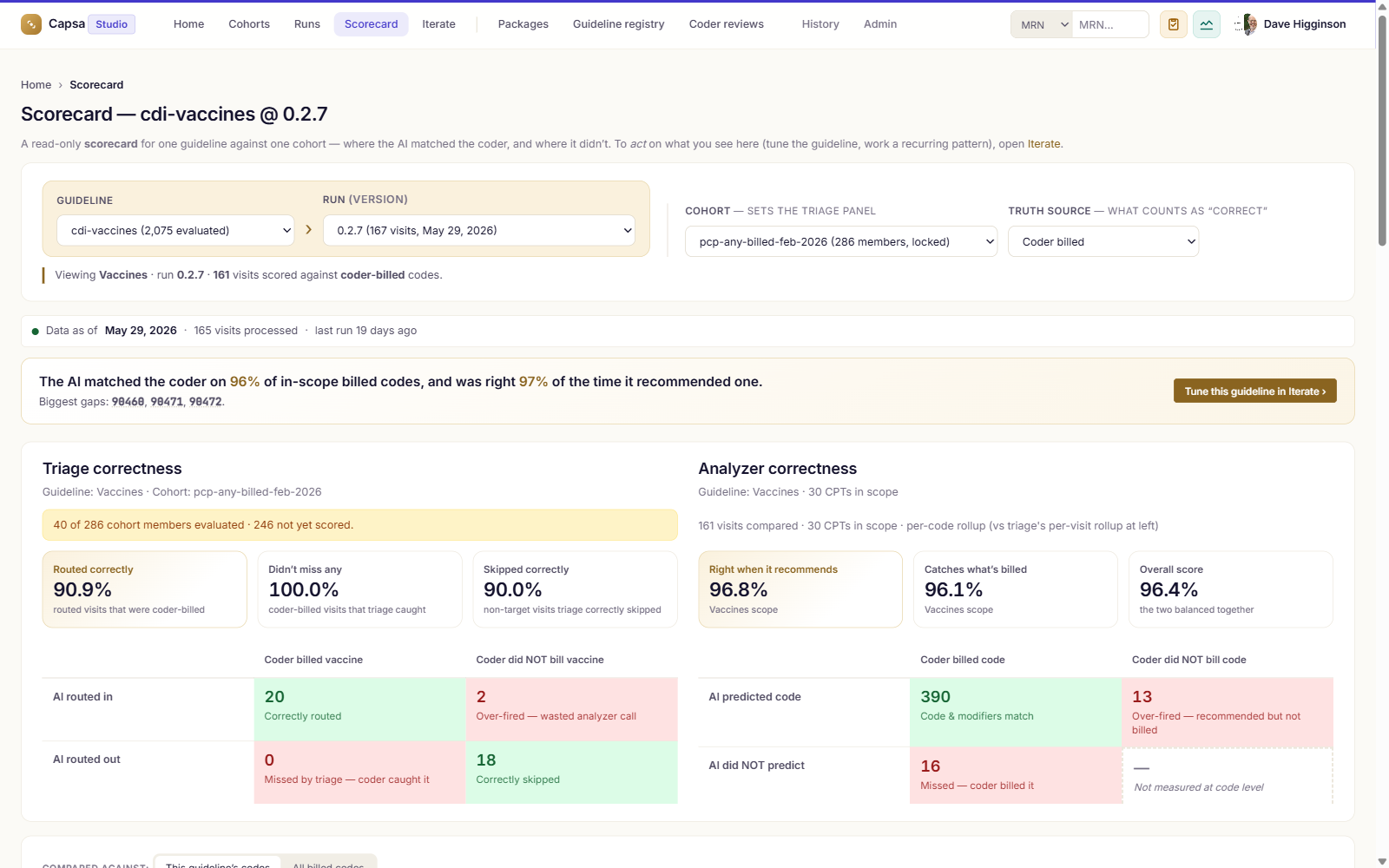
Build & prove it
Cohorts, accuracy vs what your coders billed, and a human-approved improvement loop — with version control.
Explore Studio →Transparent by design — and yours to govern.
Every code traces to the chart
Code → rule → the verbatim chart text that triggered it, at the exact version that ran. Every quote is checked word-for-word against the chart; if the words aren’t there, the code never makes it into the set.
Versioned and auditable
Rules, codes, and examples are versioned together with full history and side-by-side diffs. When a payer rule shifts, the change — and every code made under it — is on the record.
Your coding logic isn’t in a black box
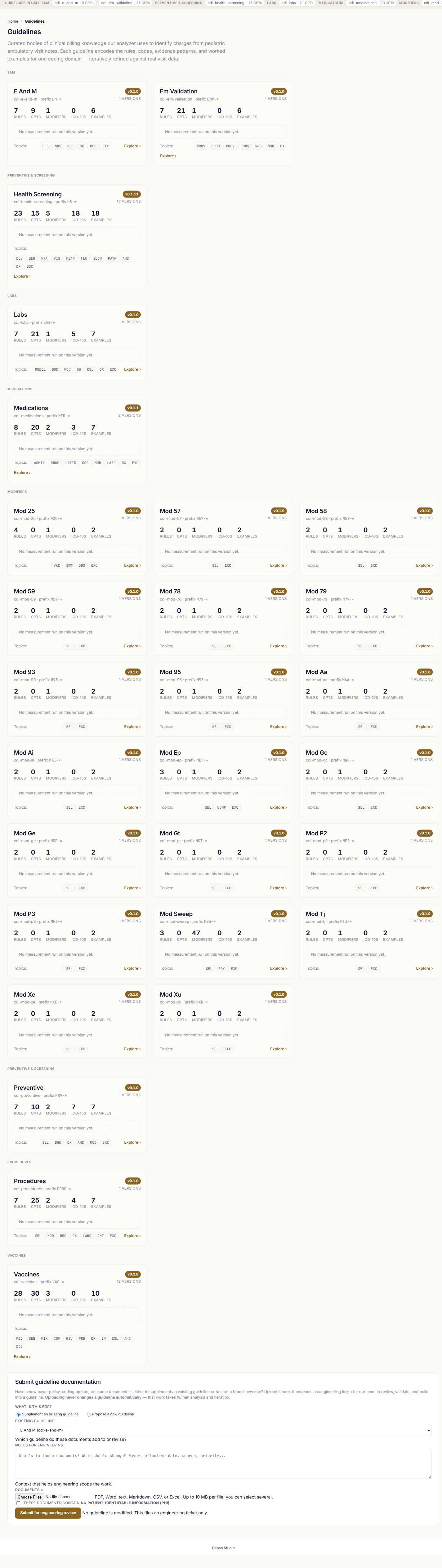
Every rule and guideline is written in plain language your team can open, read, and change — the logic is right there to inspect, not hidden where you can’t see it. The same explicit guidelines run across every category.
Flexibility to grow with you.
Start with one area of coding and grow from there — from a single category to preparing the whole bill, across new care settings as we expand. Live today across pediatric primary care:
However you buy it — to find missed revenue (Charge Capture) or to catch denials before they happen (Claim Validation) — it's the same coding underneath. See everything we cover →
Curious what Capsa would find in your charts?
Tell us a bit about your team and we'll show you what Capsa finds across your visits — on the categories you care about, measured against what your coders already billed, including the charges going uncoded today.
- Every visit coded — at a fraction of the coder hours
- Accuracy measured vs. what your coders billed
- Every recommendation cited to the chart
- No EMR or vendor lock-in
Get in touch
We'll get back to you within one business day.